Big endian and little endian
Monday, March 24, 2025
Every time I run into endianness, I have to look it up. Which way do the bytes go, and what does that mean? Something about it breaks my brain, and makes me feel like I can't tell which way is up and down, left and right.
This is the blog post I've needed every time I run into this. I hope it'll be the post you need, too.
What is endianness?
The term comes from Gulliver's travels, referring to a conflict over cracking boiled eggs on the big end or the little end[1]. In computers, the term refers to the order of bytes within a segment of data, or a word. Specifically, it only refers to the order of bytes, as those are the smallest unit of addressable data: bits are not individually addressable.
The two main orderings are big-endian and little-endian. Big-endian means you store the "big" end first: the most-significant byte (highest value) goes into the smallest memory address. Little-endian means you store the "little" end first: the least-significant byte (smallest value) goes into the smallest memory address.
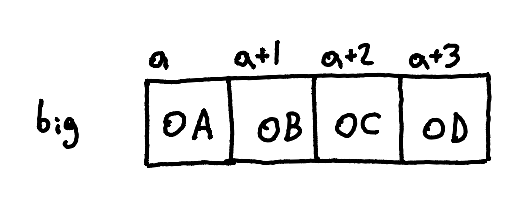
Let's look at the number 168496141 as an example. This is 0x0A0B0C0D in hex.
If we store 0x0A at address a, 0x0B at a+1, 0x0C at a+2, and 0x0D at a+3, then this is big-endian.
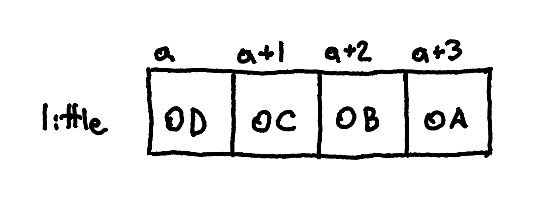
And then if we store it in the other order, with 0x0D at a and 0x0A at a+3, it's little-endian.
And... there's also mixed-endianness, where you use one kind within a word (say, little-endian) and a different ordering for words themselves (say, big-endian). If our example is on a system that has 2-byte words (for the sake of illustration), then we could order these bytes in a mixed-endian fashion. One possibility would be to put 0x0B in a, 0x0A in a+1, 0x0D in a+2, and 0x0C in a+3.
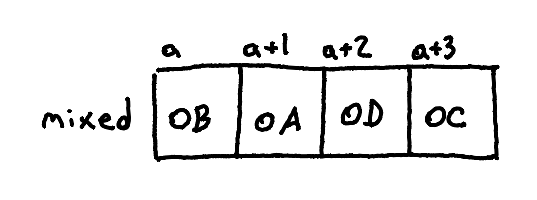
There are certainly reasons to do this, and it comes up on some ARM processors, but... it feels so utterly cursed. Let's ignore it for the rest of this!
For me, the intuitive ordering is big-ending, because it feels like it matches how we read and write numbers in English[2]. If lower memory addresses are on the left, and higher on the right, then this is the left-to-right ordering, just like digits in a written number.
So... which do I have?
Given some number, how do I know which endianness it uses?
You don't, at least not from the number entirely by itself. Each integer that's valid in one endianness is still a valid integer in another endianness, it just is a different value. You have to see how things are used to figure it out.
Or you can figure it out from the system you're using (or which wrote the data). If you're using an x86 or x64 system, it's mostly little-endian. (There are some instructions which enable fetching/writing in a big-endian format.) ARM systems are bi-endian, allowing either. But perhaps the most popular ARM chips today, Apple silicon, are little-endian. And the major microcontrollers I checked (AVR, ESP32, ATmega) are little-endian. It's thoroughly dominant commercially!
Big-endian systems used to be more common. They're not really in most of the systems I'm likely to run into as a software engineer now, though.
You are likely to run into it for some things, though. Even though we don't use big-endianness for processor math most of the time, we use it constantly to represent data. It comes back in networking!
Most of the Internet protocols we know and love, like TCP and IP, use "network order" which means big-endian. This is mentioned in RFC 1700, among others. Other protocols do also use little-endianness again, though, so you can't always assume that it's big-endian just because it's coming over the wire.
So... which you have? For your processor, probably little-endian. For data written to the disk or to the wire: who knows, check the protocol!
Why do we do this???
I mean, ultimately, it's somewhat arbitrary. We have an endianness in the way we write, and we could pick either right-to-left or left-to-right. Both exist, but we need to pick one. Given that, it makes sense that both would arise over time, since there's no single entity controlling all computer usage[3].
There are advantages of each, though.
One of the more interesting advantages is that little-endianness lets us pretend integers are whatever size we like, within bounds.
If you write the number 26[4] into memory on a big-endian system, then read bytes from that memory address, it will represent different values depending on how many bytes you read. The length matters for reading in and interpreting the data.
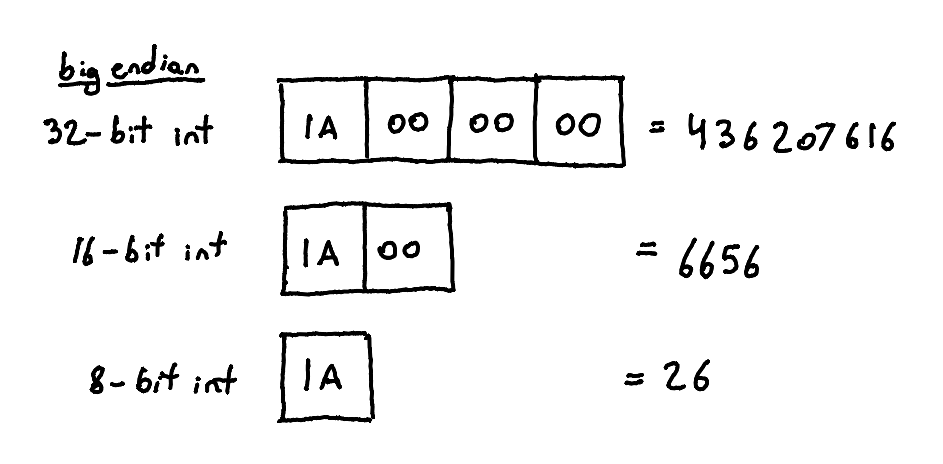
If you write it into memory on a little-endian system, though, and read bytes from the address (with the remaining ones zero, very important!), then it is the same value no matter how many bytes you read. As long as you don't truncate the value, at least; 0x0A0B read as an 8-bit int would not be equal to being read as a 16-bit ints, since an 8-bit int can't hold the entire thing.
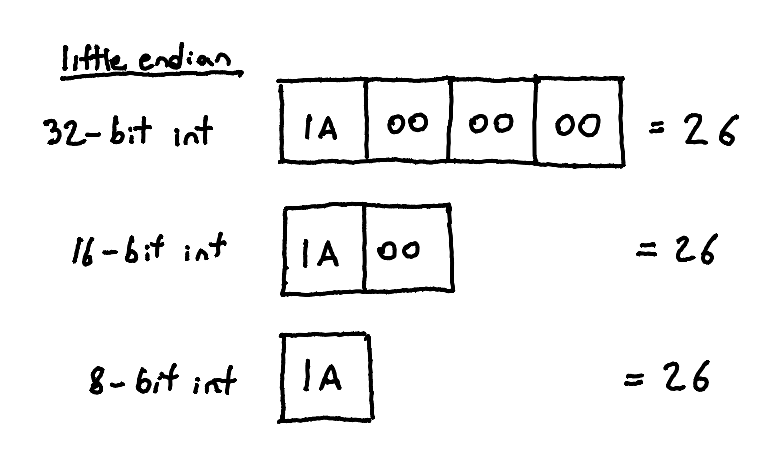
This lets you read a value in the size of integer you need for your calculation without conversion.
On the other hand, big-endian values are easier to read and reason about as a human. If you dump out the raw bytes that you're working with, a big-endian number can be easier to spot since it matches the numbers we use in English. This makes it pretty convenient to store values as big-endian, even if that's not the native format, so you can spot things in a hex dump more easily.
Ultimately, it's all kind of arbitrary. And it's a pile of standards where everything is made up, nothing matters, and the big-end is obviously the right end of the egg to crack. You monster.
-
The correct answer is obviously the big end. That's where the little air pocket goes. But some people are monsters... ↩
-
Please, please, someone make a conlang that uses mixed-endian inspired numbers. ↩
-
If ever there were, maybe different endianness would be a contentious issue. Maybe some of our systems would be using big-endian but eventually realize their design was better suited to little-endian, and then spend a long time making that change. And then the government would become authoritarian on the promise of eradicating endianness-affirming care and—Oops, this became a metaphor. ↩
-
26 in hex is 0x1A, which is purely a coincidence and not a reference to the First Amendment. This is a tech blog, not political, and I definitely stay in my lane. If it were a reference, though, I'd remind you to exercise their 1A rights[5] now and call your elected officials to ensure that we keep these rights. I'm scared, and I'm staring down the barrel of potential life-threatening circumstances if things get worse. I expect you're scared, too. And you know what? Bravery is doing things in spite of your fear. ↩
-
If you live somewhere other than the US, please interpret this as it applies to your own country's political process! There's a lot of authoritarian movement going on in the world, and we all need to work together for humanity's best, most free[6] future. ↩
-
I originally wrote "freest" which, while spelled correctly, looks so weird that I decided to replace it with "most free" instead. ↩
If you're looking for help on a software project, please consider working with me!
Please share this post, and subscribe to the newsletter or RSS feed. You can email my personal email with any comments or questions.
Want to become a better programmer?
Join the Recurse Center!
Want to hire great programmers?
Hire via Recurse Center!